Mapping the Unwritten: How Meta’s AI Agents Decoded Tribal Knowledge in Massive Data Pipelines
Meta faced a challenge common to many large engineering organizations: their AI coding assistants lacked the deep, context-rich understanding of their sprawling codebase. With a data processing pipeline spanning four repositories, three languages, and over 4,100 files, the AI agents struggled to make useful edits efficiently. To solve this, Meta built a swarm of 50+ specialized AI agents that systematically read every file and produced concise context files capturing the tribal knowledge that previously existed only in engineers' heads. The result was a structured knowledge layer that dramatically improved AI performance. Below, we explore the key aspects of this innovative approach through seven questions and detailed answers.
1. What specific problem did Meta encounter with AI coding assistants in large-scale pipelines?
When Meta pointed AI agents at their large-scale data processing pipeline—config-as-code involving Python configurations, C++ services, and Hack automation scripts—they found the agents couldn't make useful edits quickly. The AI had no map of the codebase. It didn't know critical details like that two configuration modes use different field names for the same operation (swapping them would cause silent wrong output), or that dozens of deprecated enum values must never be removed because serialization compatibility depends on them. Without this contextual awareness, agents would guess, explore, and often produce code that compiled but was subtly incorrect. The core issue was that the AI lacked the tribal knowledge—the unwritten rules and design decisions—that engineers carried in their heads. This gap made AI useless for development tasks, even though it handled operational tasks like scanning dashboards and pattern-matching against historical incidents well.

2. How did Meta's pre-compute engine with specialized AI agents work to solve this?
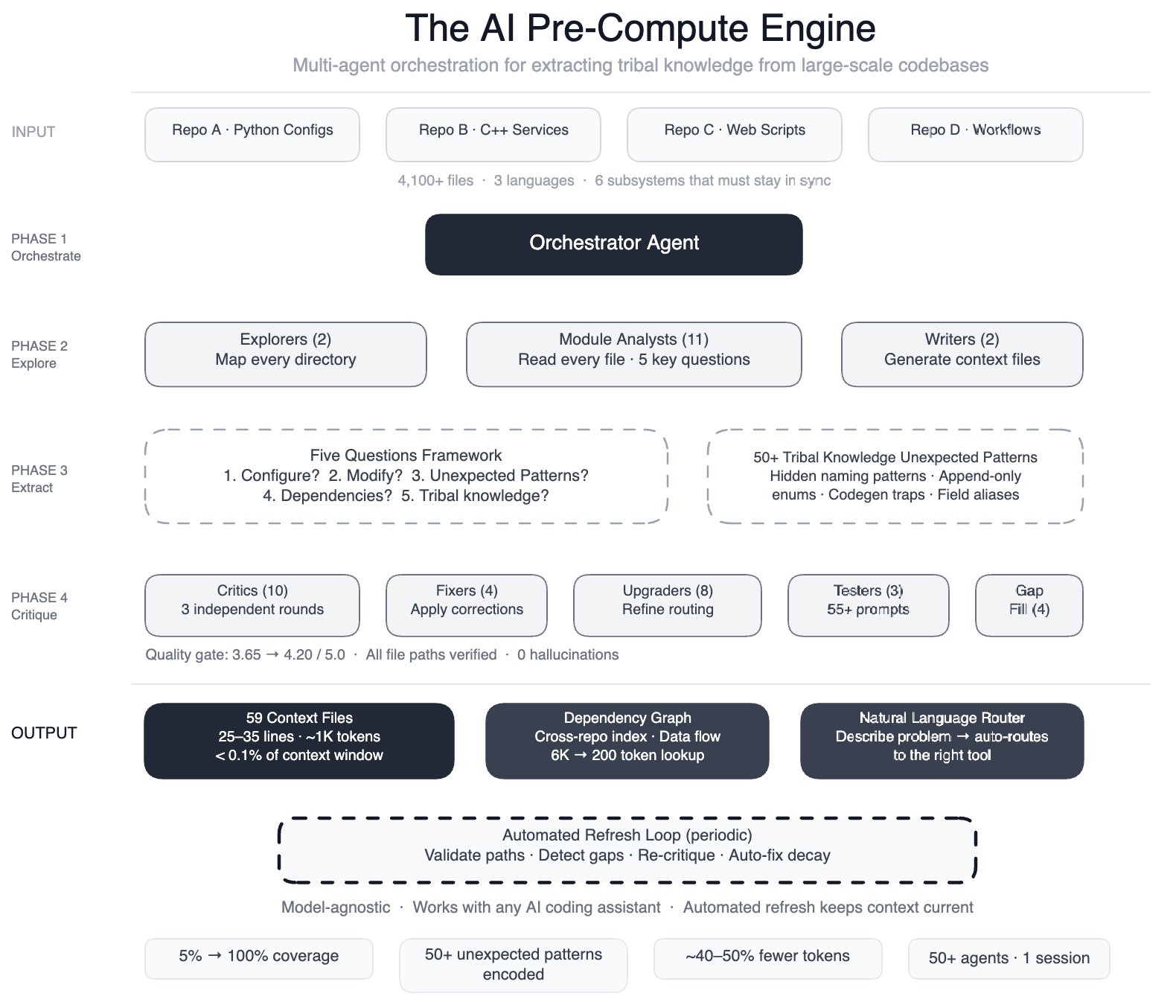
Meta built a pre-compute engine: a swarm of over 50 specialized AI agents that systematically read every file in the pipeline. The agents worked in structured phases: two explorer agents first mapped the codebase, then 11 module analysts read every file and answered five key questions about each module. After that, two writers generated 59 concise context files that encoded the tribal knowledge. The process also included multiple quality control layers: 10+ critic passes ran three rounds of independent quality review, four fixers applied corrections, and eight upgraders refined the routing layer. Finally, three prompt testers validated over 55 queries across five personas, and four gap-fillers covered remaining directories. This orchestration of 50+ specialized tasks in a single session ensured that the resulting context files were accurate, comprehensive, and usable by AI agents. The knowledge layer is model-agnostic, working with most leading AI models.
3. What were the measurable results of implementing this context-file approach?
The results were substantial. Before this approach, AI agents had structured navigation guides for only 5% of code modules. After implementing the pre-compute engine, coverage jumped to 100%—all 4,100+ files across three repositories now have context files. Additionally, the agents documented over 50 non-obvious patterns—underlying design choices and relationships not immediately apparent from the code. Preliminary tests showed a 40% reduction in the number of tool calls required per task, meaning AI agents could make useful edits faster and with less trial-and-error. The system also self-maintains: every few weeks, automated jobs validate file paths, detect coverage gaps, re-run quality critics, and auto-fix stale references. This ensures the knowledge stays up to date without manual intervention. Notably, the AI isn't just a consumer of this infrastructure—it's the engine that runs it, as the same agents that generated the context files also maintain them.
4. What does the pipeline's architecture look like, and why was tribal knowledge critical?
Meta's pipeline is config-as-code, with Python configurations, C++ services, and Hack automation scripts working together across multiple repositories. A single task like onboarding a new data field touches six subsystems that must stay in sync: configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts. The tribal knowledge consisted of subtle rules and dependencies that weren't written down. For example, certain configuration modes use different field names for the same operation—swap them and you get silent wrong output. Or that dozens of deprecated enum values must never be removed because serialization compatibility depends on them. Without this knowledge, AI agents would guess and explore, producing code that compiled but was subtly wrong, causing downstream bugs. The context files essentially acted as a map for the AI, revealing these hidden connections and constraints that developers inherently knew but code alone didn't express.
5. How did Meta structure the phased approach to create these context files?
Meta used a large-context-window model with task orchestration to structure the work in clear phases. First, two explorer agents mapped the codebase to understand its overall layout and dependencies. Then 11 module analysts read every file in detail, answering five key questions that captured essential functionality, interfaces, and hidden caveats. Two writer agents then synthesized this information into 59 concise context files. To ensure quality, over 10 critic passes ran three rounds of independent review, catching errors and inconsistencies. Four fixer agents applied corrections based on critic feedback. Eight upgraders refined the routing layer to ensure the context files were logically organized and easy to navigate. Three prompt testers validated that the context files worked well with various AI queries across five different user personas. Finally, four gap-fillers covered any remaining directories, and three final critics ran integration tests. This orchestration of 50+ specialized tasks in a single session created a robust knowledge layer.
6. Is this knowledge layer model-specific, or can it work with different AI tools?
One of the key design principles of Meta's system is that the knowledge layer is model-agnostic. This means it can work with most leading AI models, not just a specific one. The context files are structured in a way that any AI agent can leverage them as navigation guides, regardless of the underlying model architecture. The system was tested with multiple models, and the performance improvements—like the 40% reduction in tool calls—were consistent across them. This flexibility is important because it allows Meta to adopt new AI models as they become available without having to re-engineer the entire knowledge infrastructure. The knowledge layer effectively decouples domain expertise from model capabilities, making the AI tools smarter about the codebase while remaining adaptable to the rapidly evolving landscape of AI models.
7. How does the system maintain itself over time without manual effort?
The system is designed to be self-maintaining. Every few weeks, automated jobs run that perform several maintenance tasks: they validate that file paths referenced in context files still exist (preventing broken links), detect coverage gaps where new files have been added but not yet documented, re-run quality critics to ensure the context files remain accurate and useful, and auto-fix stale references that may have changed due to code updates. This entire maintenance pipeline is itself driven by AI—the same swarm of specialized agents that initially generated the context files now periodically audits and updates them. So the AI is not just a consumer of this infrastructure; it's the engine that runs it. This self-healing capability ensures that the tribal knowledge stays current without requiring manual effort from engineers, who can focus on development tasks instead of documentation.