10 Key Insights into Sakana AI's KAME: Redefining Real-Time Conversational AI
Conversational AI has long faced an impossible tradeoff: respond instantly but superficially, or wait for deep knowledge at the cost of natural flow. Now, Sakana AI—a Tokyo-based research lab—has unveiled KAME (Knowledge-Access Model Extension), a hybrid speech-to-speech (S2S) architecture that shatters this binary. By weaving together a lightning-fast direct S2S model with a powerful large language model (LLM) running in parallel, KAME achieves near-zero latency while delivering rich, contextual answers. This article unpacks the ten most critical aspects of KAME, from its technical innovations to its real-world implications.
1. The Core Tradeoff: Speed vs. Knowledge in Conversational AI
For years, developers of voice assistants faced an impossible choice: optimize for speed or for depth. Direct S2S models like Moshi (by KyutAI) respond in milliseconds—often starting before the user finishes speaking—but their limited capacity forces them to sacrifice factual accuracy and reasoning. Cascaded systems, which route speech through an ASR module, an LLM, and a TTS engine, deliver much smarter answers but suffer from a median latency of around 2.1 seconds—enough to break conversational rhythm. KAME was designed to end this dilemma, and it does so by keeping both pipelines active simultaneously.
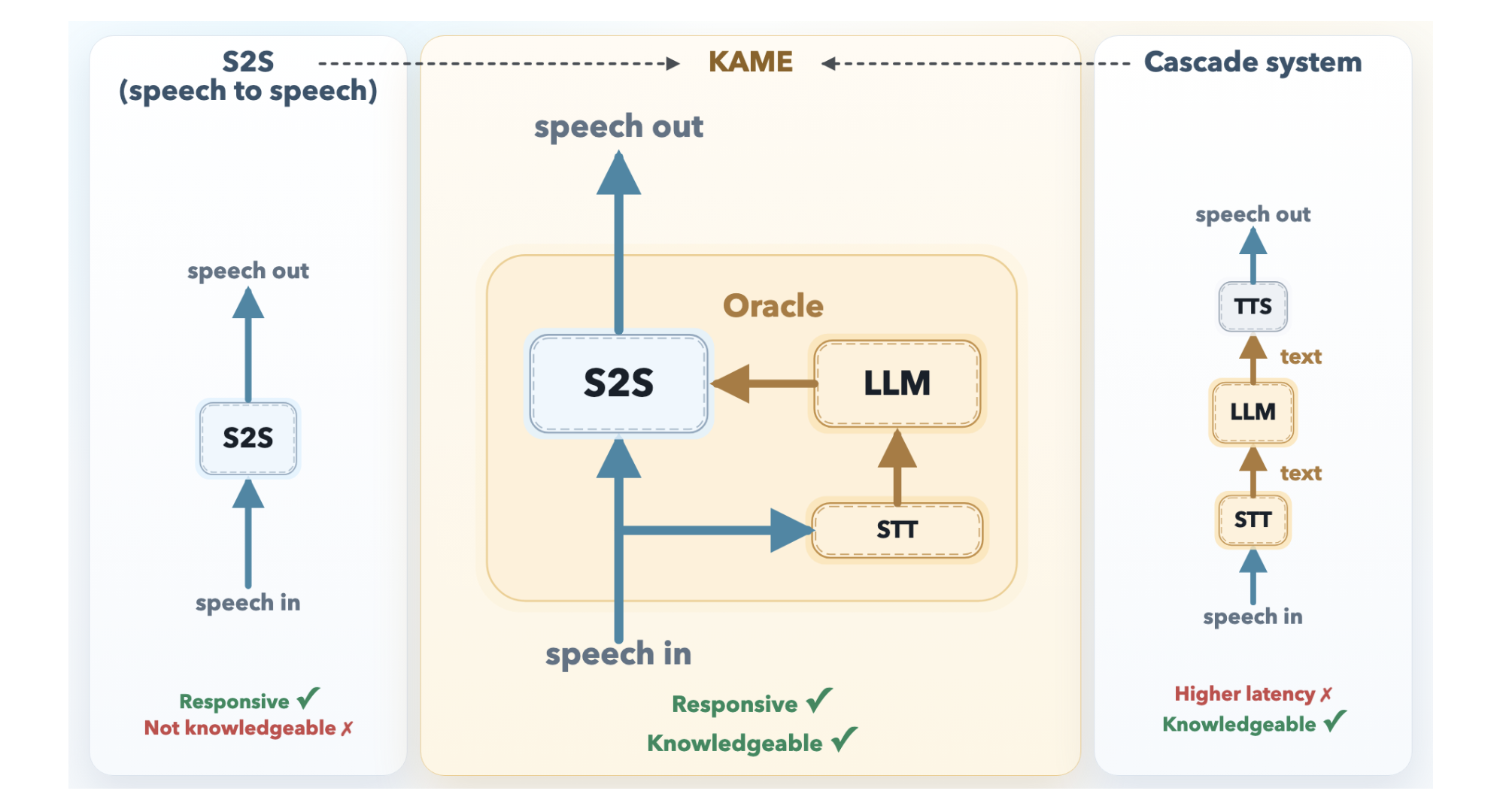
2. Direct S2S Models: The Fast but Shallow Path
Direct S2S architectures, such as Moshi, operate as monolithic transformers that ingest audio tokens and output audio tokens in a continuous loop. Their primary advantage is latency: they can begin uttering a response within 80 milliseconds, often overlapping with the end of the user's question. However, acoustic signals carry far more information than text—pitch, emotion, rhythm, and tone consume a huge portion of the model's capacity. Consequently, the model has little room left for storing factual knowledge or performing deep reasoning. The result is a voice that sounds natural but offers shallow, sometimes irrelevant answers.
3. Cascaded Systems: The Smart but Slow Path
Cascaded systems take the opposite approach: they transcribe user speech into text (ASR), feed that text into a powerful LLM, and convert the LLM's response back into speech (TTS). The knowledge quality is superb because the system can leverage any frontier LLM—GPT-4, Claude, or others. But the pipeline is inherently sequential: the system must wait for the user to stop speaking before ASR and LLM processing begin. This introduces a median latency of about 2.1 seconds, which feels unnatural and robotic. Users often interrupt or feel the conversation is stilted. KAME eliminates this wait.
4. KAME as a Hybrid: Speaking While Thinking
KAME's key insight is that the two paradigms can run in parallel, not sequentially. The system uses a tandem architecture where a front-end S2S module (based on Moshi) processes audio in real time and begins generating a spoken response immediately. Meanwhile, a back-end module runs a streaming speech-to-text (STT) component paired with a full-scale LLM. As the user speaks, the STT continuously builds a partial transcript and sends it to the LLM. The LLM's candidate responses—called oracles—are fed back to the front-end model, which injects the knowledge into its ongoing speech output without restarting.
5. The Oracle Stream: A Fourth Dimension for Knowledge
The original Moshi architecture uses three streams: input audio, inner monologue (text), and output audio. In KAME, a fourth stream—the oracle stream—is added. This stream carries candidate text responses from the back-end LLM, which are computed on partial transcripts as the user speaks. The front-end S2S model can then incorporate these oracles into its output audio generation, effectively injecting factual knowledge and reasoning into the fast speech pipeline. This design ensures that the final spoken response benefits from both the natural cadence of a direct S2S model and the depth of an LLM.
6. Asynchronous Processing: The Secret to Zero Latency
KAME's tandem components run asynchronously. The front-end S2S module operates on a fixed cycle of 80-millisecond audio tokens, generating output without waiting for the LLM. The back-end LLM, meanwhile, processes partial transcripts continuously, sending updates whenever a new oracle is ready. Because the two streams are decoupled, the system never pauses for the LLM. If the LLM is slow or fails, the front-end model can still produce a sensible (but shallow) response. This architecture guarantees near-zero latency even when the LLM requires significant time to reason about complex queries.
7. Latency Improvements: From Seconds to Milliseconds
Quantitatively, KAME reduces the perceptible delay of cascaded systems from roughly 2.1 seconds to under 200 milliseconds—often closer to 80 milliseconds. More importantly, the system can start speaking before the user finishes their sentence, mimicking the natural turn-taking of human conversation. This is achieved because the front-end model begins generating output audio immediately, and only later refines it using the oracles from the LLM. The user perceives a single, fluid response rather than a series of disjointed processing steps. Such low latency is critical for applications like real-time interpreting, customer support, and interactive voice agents.
8. Knowledge Quality: Matching Frontier LLMs Without Sacrifice
KAME does not need to compress all knowledge into the S2S model. Instead, it leverages any off-the-shelf LLM as the back-end. This means the system can access the latest factual updates, complex reasoning capabilities, and large-scale knowledge bases without requiring retraining of the speech module. In internal tests, KAME demonstrated answer accuracy and reasoning depth comparable to cascaded systems using GPT-4, while maintaining the responsiveness of a direct S2S model. The oracle stream effectively acts as a real-time knowledge injection channel, updating the S2S output on the fly.
9. Integration with Existing Voice Assistants
Because KAME is designed as an extension rather than a full replacement, it can be retrofitted onto existing direct S2S models. The key components—the oracle stream and the streaming STT/LLM pipeline—are modular. Developers can attach KAME to a Moshi-based front-end or even to other lightweight S2S models. The back-end LLM can be swapped based on cost, domain, or privacy requirements. This modularity makes KAME a practical upgrade path for companies that already have voice assistants deployed, as they can enhance intelligence without overhauling the core speech engine.
10. Future Directions and Open Challenges
KAME's architecture opens several research avenues. One challenge is ensuring that the oracles arrive in time for the front-end model; if the LLM is too slow, the response may revert to shallow output. Another is handling multiple oracle candidates—deciding which knowledge to inject when competing facts appear. Sakana AI also plans to explore fine-tuning the S2S model to better utilize the oracle stream, potentially allowing it to dynamically weigh or query the LLM for specific information. Beyond voice assistants, KAME could power real-time translation, AI companions, and interactive storytelling where fluency and depth are equally important.
Conclusion
Sakana AI's KAME marks a significant milestone in conversational AI, proving that speed and knowledge are not mutually exclusive. By running a direct S2S model and an LLM in parallel, and using a novel oracle stream to bridge them, KAME delivers responses that are both immediate and intelligent. This architecture could redefine user expectations for voice interactions, making stilted robot voices a thing of the past. As the lab continues to refine the system, we may soon see KAME-powered assistants that feel as natural and knowledgeable as a human conversation partner.